最近、長いタイトルを...で省略しているのあるけど...
twitterでひとりキレまくっていたけど、冷静に考えるとどうでもいい気がしてきた話のまとめ。
- ultraistter
- # 最近、長いタイトルを...で省略しているのあるけど、アレ、見た目だけのデザインを重視してUIからみえるデータのidentificationを破滅させている。ep 8を探すにはプレイリストのタイトルをひとつずつフォーカスしてtooltipを確認しないとダメでリストの意味がない。9:53 AM May 1st from P3:PeraPeraPrv
- ultraistter
- # 全単語数-1..3の組み合わせでマッチする別のデータを探して(1/ヒット数)が大きくなるグループの単語は識別に重要な情報なので単語の重要度上げて〜とかでep8が特に大きくなるはずなので、その付近をできるだけ保存した状態で後ろのほうを省略してN文字にする、みたいなアルゴリズム無いの10:01 AM May 1st from P3:PeraPeraPrv
- ultraistter
- # @fuba あるデータの長いタイトルを省略する場合にできるだけデータの識別に役立つ単語を残して省略(要約?)したい、具体的にはこのリストでepが見えるように省略したい http://gyazo.com/a0f524b67a9b79435a4692ea3f1862a1.png 10:09 AM May 1st from P3:PeraPeraPrv
- ultraistter
- # したいというか、そういうのが存在しててごく普通に使われる世界を求めている10:10 AM May 1st from P3:PeraPeraPrv
- ultraistter
- # 運用は難しいのだろうか、ただ単純にぶった切るのはかなりテキトウな方法なのでそれよりもう少しマシな方法はないのかと思ったんです。10:23 AM May 1st from P3:PeraPeraPrv
- ultraistter
- # "Melancholy Haruhi-chan", "Melancholy Suzumiya"とかに比べて"Suzuymiya ep8", "Melancholy ep8"とかは急激に頻度が少なくなる(はず)なので、ep8があやしい!残せ!みたいなことを言いたかった10:40 AM May 1st from P3:PeraPeraPrv
- ultraistter
- # 最悪Playlist内だけとかRelated Videosだけでいいんですよ、省略されているのはそこだけだし、そこは似たタイトルが選ばれて出てきているはずなのに似た部分だけ残して省略されててなんやそれと気になった10:43 AM May 1st from P3:PeraPeraPrv
- ultraistter
- # グリモンでできそうな気がしてきたけどやめよう10:49 AM May 1st from P3:PeraPeraPrv
- ultraistter
- # 寝るのに失敗したので、昨日言ってたyoutubeのグリモン作ろうとしてるけど、firebug使えないんだっけ…約3時間 ago from P3:PeraPeraPrv
- ultraistter
- # 特定のケースについてはできた http://gyazo.com/1a6c66e8b44db61c36d57fe6c1d5f646.png
- ultraistter
- 大体できてる気はするけど、そもそも長いタイトルが稀な気がしてきた http://gyazo.com/0775fffbe12d6bd5f26f91ae52e89921.png
- ultraistter
- # グリモン、ソースコード的な意味で置いた http://tinyurl.com/dc8aft 約1時間 ago from P3:PeraPeraPrv
- ultraistter
- # 日本語はバラせないので無理だ、MeCab.jsがいる44分 ago from P3:PeraPeraPrv
- ultraistter
- # 日本語はグリモンからYahooの形態素解析APIに投げればいいのか、とりあえずはやらない…20分 ago from P3:PeraPeraPrv
- ultraistter
- # デベロッパーIDがいるから無理か、自前でMeCab.cgi置けばいいけど、さすがに・・・という18分 ago from P3:PeraPeraPrv
- ultraistter
- リストの中でさらに階層を持たないとダメな感じだ…、「作者 タイトル(10個くらい) 章(1〜3)」とかだと、「作者...タイトル」になってしまう。ただ制限文字数が少ないのであまりがんばっても意味不明な文字列を並べた感じになってしまう。
{kind=link}
{kind=link}
{kind=link}
ハルヒちゃんはネタです。
普通にありそうなんですけど、手抜きながらもとりあえず動くものを作った。
after←before
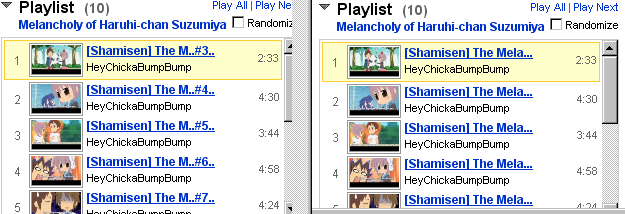
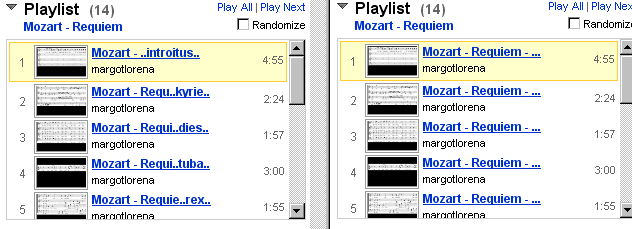
http://www.udp.jp/misc/userscript/youtube_playlist_summari.user.js
// ==UserScript== // @name youtube playlist !!!smart!!! summarizer // @namespace http://www.udp.jp/ // @include http://www.youtube.com/*feature=PlayList* // ==/UserScript== // Youtubeのプレイリストで // タイトルが前からN文字でぶった切られて識別不能になることがあるので // データの識別に役立ちそうな情報を残して省略するもの // after<-before http://gyazo.com/325f12ff6253b79dfc6fe762655aeac5.png function getTitleNode(o) { var child = o.childNodes; for (var i = 0; i < child.length; ++i) { if (child[i].className == "vtitle") { return child[i]; } } return null; } function getPlaylist() { var div = document.getElementsByTagName("div"); var playlist = new Array(); for (var i = 0; i < div.length; ++i) { if (div[i].className == "watch-playlist-row-middle") { var node = getTitleNode(div[i]); if (node) { var title = new String(node.title); title.update = (function (o) { return function (new_title) { o.textContent = new_title; }; })(node); playlist.push(title); } } } return playlist; } function summarize(n, str, list) { var i, j, m; var token = str.split(/[ \{\}\[\]\(\)]+/); var id_token = new Object; var comp_str = ""; for (i = 0; i < token.length; ++i) { token[i] = new String(token[i].toLowerCase()); token[i].freq = 0; } // strの2単語の組み合わせについてlist内の頻度を計算 for (i = 0; i < token.length; ++i) { for (j = i + 1; j < token.length; ++j) { var freq = 0; for (m = 0; m < list.length; ++m) { var lc = list[m].toLowerCase(); if (lc.indexOf(token[i]) != -1 && lc.indexOf(token[j]) != -1) { ++freq; } } token[i].freq += freq; token[j].freq += freq; } } token.sort(function(a, b) { return a.freq - b.freq; }); // 頻度の一番少ないのをidということに… // (本当は[一番]とかではなくソフトな感じでやりたい) id_token.text = token[0]; id_token.index = str.toLowerCase().indexOf(token[0]); id_token.length = token[0].length; // ...省略 if (n <= id_token.length) { // id がnと同じか長い comp_str = id_token.text.substr(0, n); } else if (id_token.index + id_token.length <= n - 2) { // id位置までnに十分入る if (n < str.length) { comp_str = str.substr(0, n - 2) + ".."; } else { comp_str = str; } } else { // idの前方省略 if (id_token.index + id_token.length < str.length) { comp_str = str.substr(0, n - id_token.length - 4) + ".." + id_token.text + ".."; } else { comp_str = str.substr(0, n - id_token.length - 2) + ".." + id_token.text; } } return comp_str; } var playlist = getPlaylist(); for (var i = 0; i < playlist.length; ++i) { playlist[i].update(summarize(22, playlist[i], playlist)); }
@fuba様および@penguinana様にはヒントをいただきました。