National Data Science Bowl 10位
プランクトン画像分類コンペこと National Data Science Bowl が終わりました。
Description - National Data Science Bowl | Kaggle
結果はタイトル通り10位(1049チーム中)でした。賞金2000万円が1円も貰えなかったショックで毎日15時間くらい寝ています。感想と投稿内容です。
感想
世界Deep Convolutional Neural Networks職人コンテストという感じでした。みんな強かったです。前半は、2〜5位くらいにいる状態だったので、これは賞金はオレのものだなHAHAHAなどと思っていたのですが、終盤は15位くらいまで押し出されるようになり、こいつらマジかよ、強すぎだろ、と思って、最後方向転換をしてどうにか10位で終われました。自分の感覚ではスコア(NLL)で0.7以下を出せれば、Deep CNNを熟知していて必要な処理を漏れなくやった上で相当チューニングしているという印象なのですが、これが最終的に50人以上いました。そんなにいるとは思わなくて、世界をなめていたと思います。
また自分でやりながら0.6くらいが限界だと思っていたのですが、上位3チームは飛び抜けて良いスコアを出していて、そこを超えているので、本当にすごかったと思います。入賞がちょうど3チームなので、まぁ...あそこにはどうやっても入れなかったな、と諦めがつくくらいです。
ということで、賞金は貰えず、ぎりぎり10位*1という微妙な結果だったので、10位だったことくらいは自慢させてください。10位!!
投稿内容
概要
前半は、ひとつのCNNのアーキテクチャをとにかくチューニングして、それを8個学習して平均するという、シンプルな手法を採用していました。
が、終了1週間前の時点で、これではTOP10にも入れないと判断したので、最後の1週間で、入力サイズの異なる3つのアーキテクチャ(48x48, 72x72, 96x96)を8ずつ計24個のCNNを20台のGPUマシンで4日くらいかけて学習して各予測値を線形モデルでアンサンブルするという、激重な手法に切り替えました。これは"色々混ぜればスゴイ"という適当な考えではなくて、データセットの画像サイズがバラバラ(幅32px〜400pxくらいがある)なので、予測時の適切な解像度は画像ごとに異り、異なる入力サイズのアーキテクチャをアンサンブルすればスコアは改善できるだろうという推測が初期の頃からありました(ただダサいのであまりやりたくなかった)。結果うまくいって、ぎりぎり10位で終われました。結局やるのなら初めからやっておけばもう少し良く出来たかもしれません。
前処理
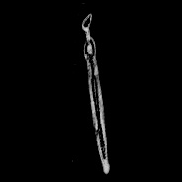
このデータセットは、画像ごとにサイズが異なり、また正方形でもありません。一般的なCNNでは固定サイズで正方形の画像を入力とするので、以下の方法で変換しました。
- パディングで補って元画像の2倍のサイズにする
- 意味のある値が入っているピクセルが全て含まれる領域を矩形で囲う
- 矩形の縦、横で長い方のサイズを1辺の長さとする正方形で切り抜く
- 明度を反転(元画像の背景が白なのを黒にする)
| 入力 | 出力 |
|---|---|
 |
 |
 |
 |
 |
 |
中央寄せして、パディングで正方形にして、画素値を反転させます。画素値を反転するのはその後の画像処理で背景が0となっていたほうが扱いやすいからで、精度等とは関係ありません。
いきなりですが、中央寄せの効果については、検証していません。画像によってはプランクトンが端っこにいて、後のdata augmentationと合わせて最悪なことになりそうなので中央寄せしたほうがいいだろうと思ってやっているのですが、最初のプログラミング時点からやっていたので、これに意味があるか、または逆に悪くなっていないか等は分かりません。上位には入れているのでそんなに悪くはないと思います。
Data augmentation
- データが少なすぎるクラスがいくつかある
- プランクトン画像には、回転や位置ズレ、姿勢の違いなど様々な変動がありえる
といった理由から、data augmentation(学習データの人工的な拡大)でスコアが改善すると思ったので行いました。
またオフラインのdata augmentationではなくオンライン(real-time)のdata augmentationが特に効果的でした。
data augmentationには次の変形を使いました。
- translation (位置の変形, シフト)
- scaling (対象サイズの変形, ズームアウト/ズームイン)
- rotation (回転)
- horizontal reflection (左右反転)
- parspective cropping (affine変換またはhomography変換による変形)
- コントラスト変更
これらの変形メソッドとその変形パラメーターをランダムに組み合わせることで1枚の画像から以下のような改変バージョンをムゲンに生成して学習データとします。

変形が分かりやすいようグリッドで表すと次のようになります。

real-time data augmentationでは、(オンライン)学習器にデータを与える際にこのランダムな変形を通してから渡すようにします。変形のパターンが十分あれば、学習中に同じデータは1度しか与えられないので、オーバーフィッティングしにくくなります。
自分の実験では、シングルモデルでdata augmentationのあり/なしを変えた時のスコアは以下のようになっています。
| 学習時のdata augmentation | 予測時のdata augmentation | スコア(順位) |
|---|---|---|
| なし | なし | 1.46 (400位くらい) |
| あり | なし | 0.77 (120位くらい) |
| あり | あり | 0.65 (35位くらい) |
予測時のdata augmentationは、1位の方がTTA(test-time augmentation)と言っている手法で、予測対象の画像をdata augmentationで増加させた後で各パターンについて予測を行い、予測結果を平均しています。
表から分かるとおり、data augmentationは非常に効果がありました。これをやるかやらないかまたその内容によって大まかな順位が決まったと思います。
またコンペ前半に、TheanoやTorchなどプログラミングを前提としているフレームワークを使っている勢が強かったのは、この処理を早くから採用していたからだと思います(僕は最初の投稿時からやっていました)。Caffeではこの処理を入れるのに本体の改造が必要だったので、フォーラムでreal-time data augmentationが効くという話が出始めた後で本体を改造し始めた人が多かったのではと思います。
データの正規化
CNNでよく使われる正規化は、平均画像を引くというものですが、今回はGlobal Contrast Normalization(GCN)を使いました。
これは、画像ごとに画像内の平均画素値を引いて画素値の標準偏差で割るという正規化です。
データセットの平均画像はreal-time data augmentationのハイパーパラメーターによって変わるので扱いづらく、画像単位で処理できるGCNが扱いやすかったのと、収束やスコア的にも問題なかったので選択しました。
ちなみにデータの正規化は、data augmentationの後に行っています。real-timeの場合は、
1. データの選択
2. ランダム変形
3. 正規化
4. 学習器の更新
が学習のメインループになります。
アーキテクチャ
終了1週間前まで96x96を入力サイズとするシングルアーキテクチャ(cnn_96x96)をずっと調節していました。
いくつかスコアが上がった変更は、
- OxfordNet(VGG)ベースからHe et al. のModel Cベースに変更、初期化処理も合わせて変更、ReLUをVery Leaky ReLU(negative slope = 0.333)に変更 (PReLUではない)
- NAG で最適化するようにした
- 学習率のスケジューリングを調節
くらいです。シングルモデルで0.7→0.65くらいの改善で、頑張っていた割にあまり改善できていませんが、0.7〜0.63くらいの密度が高かったのでコンペ的には効果があったと思います。
cnn_96x96の最終盤は次のようになっています。
require 'cunn' require 'cudnn' require './LeakyReLU' -- this architecture inspired by the work of http://arxiv.org/abs/1502.01852 local ALPHA = 0.333 function cudnn.SpatialConvolution:reset(stdv) if stdv then stdv = stdv * math.sqrt(3) else stdv = math.sqrt(2 / ((1.0 + ALPHA * ALPHA) * self.kW * self.kH * self.nOutputPlane)) end self.weight:normal(0, stdv) self.bias:normal(0, stdv) end function nn.Linear:reset(stdv) if stdv then stdv = stdv * math.sqrt(3) else stdv = math.sqrt(2 / ((1.0 + ALPHA * ALPHA) * self.weight:size(2))) end self.weight:normal(0, stdv) self.bias:normal(0, stdv) end local function create_model() local model = nn.Sequential() -- input: 1x96x96 model:add(cudnn.SpatialConvolution(1, 64, 7, 7, 2, 2, 3, 3)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialMaxPooling(2, 2, 2, 2)) model:add(cudnn.SpatialConvolution(64, 128, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(128, 128, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(128, 128, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(128, 128, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialMaxPooling(2, 2, 2, 2)) model:add(nn.Dropout(0.25)) model:add(cudnn.SpatialConvolution(128, 256, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(256, 256, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(256, 256, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(256, 256, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(256, 256, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(256, 256, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialMaxPooling(2, 2, 2, 2)) model:add(nn.Dropout(0.25)) model:add(cudnn.SpatialConvolution(256, 320, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(320, 320, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(320, 320, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(320, 320, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(320, 320, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialConvolution(320, 320, 3, 3, 1, 1, 1, 1)) model:add(nn.LeakyReLU(ALPHA)) model:add(cudnn.SpatialMaxPooling(2, 2, 2, 2)) model:add(nn.Dropout(0.25)) model:add(nn.View(320 * 3 * 3)) model:add(nn.Linear(320 * 3 * 3, 1024)) model:add(nn.LeakyReLU(ALPHA)) model:add(nn.Dropout(0.5)) model:add(nn.Linear(1024, 1024)) model:add(nn.LeakyReLU(ALPHA)) model:add(nn.Dropout(0.5)) model:add(nn.Linear(1024, 121)) model:add(nn.SoftMax()) return model end return create_model
最初の頃はこんな深いネットワークは学習できませんでしたが、初期化処理を改善するのとLeakyReLUを使うのとで学習が可能になりました。
ただ悲しいことに、最後の1週間において勘で追加した入力を72x72とするアーキテクチャのほうが良いスコアを出しています。これは、入力画像サイズをチューニングしたのが最初の頃で、その後の様々な変更で適切なサイズが変わっていたのに気づかず、ずっと96x96の上で調節していたということだと思います。色々な所のハイパラーパラメーターが依存関係にあるのでもはや人類にはチューニング不可能だと思いました。
アンサンブル
上記のcnn_96x96の他に、cnn_72x72とcnn_48x48を追加してアーキテクチャごとに8個バギングした予測結果をさらに重みづけてアンサンブルしました。
アンサンブルの重みは、validationの結果から解析的に求められますが、実装が面倒だったので乱数の総当りで決めました。
最終的に各モデルの結果は次のようになりました。
| Model | Public LB score |
|---|---|
| cnn_48x48 single model | 0.6718 |
| cnn_72x72 single model | 0.6487 |
| cnn_96x96 single model | 0.6561 |
| cnn_48x48 average of 8 models | 0.6507 |
| cnn_72x72 average of 8 models | 0.6279 |
| cnn_96x96 average of 8 models | 0.6311 |
| ensemble (cnn_48x48(x8) * 0.2292 + cnn_72x72(x8) * 0.3494 + cnn_96x96(x8) * 0.4212 + 9.828e-6) | 0.6160 |
ソースコードは以下のURLで公開しています。
Kaggle-NDSB
まとめ
自分で書いてて、きわめて普通だなーと思いました。
上位3人の手法にはそれぞれ奇抜なものが含まれているようなので興味のある方はフォーラムを監視するのがよいと思います。
*1:KaggleではTOP10が概要ページのLeaderboardに表示される人数であり、Master statusの条件